Load가 높다/낮다고 표현하는 이 값의 의미는 무엇이고 시스템에 어떤 영향을 미치는지, 그리고 이 값을 바탕으로 시스템의 부하를 어떻게 결정하면 좋을지를 살펴보자.
Load Average
프로세스의 상태 중 R과 D 상태에 있는 프로세스 개수의 1분, 5분, 15분마다의 평균 값
얼마나 많은 프로세스가 실행 혹은 실행 대기 중이냐를 의미하는 수치이다.
프로세스의 수를 세는 것이기 때문에 시스템에 있는 CPU Core 수가 몇 개냐에 따라 각각의 값은 의미가 상대적이다.
ex. 하나의 Run Queue에 두 개의 프로세스가 있는 경우(CPU Core가 1개)와 서로 다른 CPU의 Run Queue에 두 개의 프로세스가 있는 경우(CPU Core가 2개) 모두 Load Average 값은 2의 근사값이 나올 것이다.
전자의 경우 한 번에 하나만 실행되기 때문에 나머지는 대기 상태 → 현재 시스템이 처리할 수 있는 프로세스보다 조금 더 많은 프로세스가 있다.
후자의 경우 동시에 실행 → 현재 시스템에서 처리할 수 있는 만큼의 프로세스가 있다.
계산 과정
root@worker1:~# uptime
06:17:52 up 6:46, 1 user, load average: 1.31, 0.50, 0.23
uptime 명령 분석
root@worker1:~# strace -s 65535 -f -t -o uptime_dump uptime
06:18:21 up 6:46, 1 user, load average: 1.11, 0.53, 0.25
root@worker1:~# ls
uptime_dump
strace 명령어는 시스템 콜들과 시그널들을 추적하기 위해 사용된다.
- -f 는 자식 프로세스를 동일한 파일에 캡처하게하고, 추적 출력에서 별도의 프로세스들의 앞에는 PID 번호가 붙는다
- -t 는 각 라인의 시작 시간을 출력한다.
- -o 는 출력이 길어서 실시간 분석이 어려울 수 있기 때문에 파일에 추적을 출력한다.
root@worker1:~# tail uptime_dump
224519 06:18:21 close(4) = 0
224519 06:18:21 openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 4
224519 06:18:21 lseek(4, 0, SEEK_SET) = 0
224519 06:18:21 read(4, "1.11 0.53 0.25 1/563 224519\\n", 8191) = 28
224519 06:18:21 fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0), ...}) = 0
224519 06:18:21 write(1, " 06:18:21 up 6:46, 1 user, load average: 1.11, 0.53, 0.25\\n", 61) = 61
224519 06:18:21 close(1) = 0
224519 06:18:21 close(2) = 0
224519 06:18:21 exit_group(0) = ?
224519 06:18:21 +++ exited with 0 +++
파일의 마지막 부분을 보면 uptime 명령은 /proc/loadavg 파일을 열어서 그 파일의 내용을 읽어 출력해주는 명령인 것을 알 수 있다.
root@worker1:~# cat /proc/loadavg
0.34 0.30 0.25 1/547 228319
그렇다면 이 값들은 어떻게 만들어지는가?
커널 코드 확인해보자. /proc 파일 시스템과 관련된 커널 소스는 fs/proc/ 에 위치해 있다.
직접 확인이 불가능하여 kernel.org에서 커널 버전을 찾아 진행했다. 본인의 경우 5.15.0-88-generic으로 5.15.153을 참고했다.
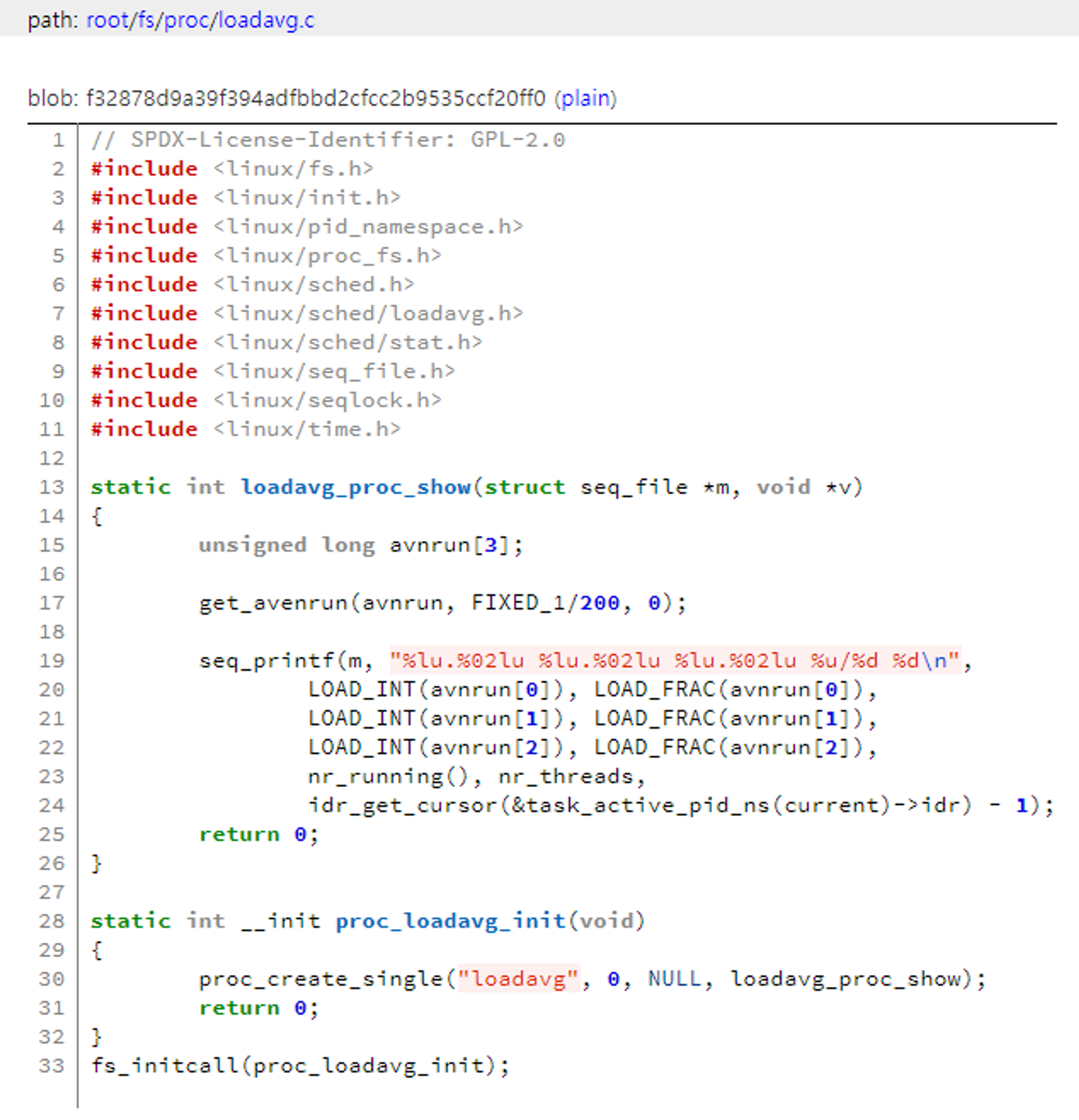
15번째 줄: avnrun이라는 배열
17번째 줄: get_avnrun() 함수를 통해 avnrun 배열에 값을 입력
19번째 줄: avnrun 배열 값을 토대로 Load Average 출력
결국 계산하는 함수는 get_avnrun()으로 이를 찾아야 한다. 다음과 같은 명령으로 찾을 수 있다.
grep -R get_avnrun ./*
실제로 계속 따라가보면 확인하고자 하는 코드는 calc_global_load() 함수에 있다.

366번째 줄: calc_load_tasks 값을 atomic_long_read()라는 매크로를 통해서 읽어온 후 active 값에 넣는다.
369번째 줄: active 값을 바탕으로 avenrun[] 배열에 있는 값들을 calc_load() 함수를 이용해서 계산한다.
그렇다면 active 값인 calc_load_tasks를 찾아보자.

395번째 줄: delta가 0이 아니면 해당 값을 calc_load_tasks 변수에 입력한다.

83번째 줄: nr_active 변수에 Run Queue를 기준으로 nr_running 상태의 프로세스 개수를 입력한다. 이 프로세스들이 바로 R 상태의 프로세스이다.
84번째 줄: nr_active 변수에 Run Queue를 기준으로 nr_uninterruptible 상태의 프로세스 개수를 더해준다. 이 프로세스들이 바로 D 상태의 프로세스이다.
86 ~ 87번째 줄: delta는 nr_active 값이 기존에 계산된 값과 다르다면 그 차이의 값에 해당한다.
정리하면 다음과 같은 흐름이 된다.

계산하는 순간을 기준으로 nr_running 상태의 프로세스 개수와 nr_uninterruptible 상태의 프로세스 개수를 합한 값을 바탕으로 계산되는 것이다.
CPU Bound vs I/O Bound
Load Average가 높다는 것은 I/O에 병목이 생겨서 I/O 작업을 대기하는 프로세스가 많을 수도 있다는 의미이다. Load Average 값만으로는 시스템에 어떤 상태의 부하가 일어나는지 확인하기 어렵다는 뜻이기도 하다.
부하를 일으키는 프로세스는 크게 2가지로 나눌 수 있다.
- CPU 자원을 많이 필요로 하는 CPU Bound (nr_running)
- 많은 I/O 자원을 필요로 하는 I/O Bound (nr_uninterrunptible)
어떤 부하인지는 중요하다. 부하의 종류에 따라 해결 방법이 달라지기 때문이다.
부하의 정체 확인하기
그렇다면 부하의 원인은 어떻게 확인할 수 있을까?
vmstat
root@worker1:~# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 103484 31912 757456 0 0 103 192 352 600 6 3 91 0 0
r: 실행되기를 기다리거나 현재 실행되고 있는 프로세스의 개수, nr_running
b: I/O를 위해 대기열에 있는 프로세스의 개수, nr_uninterruptible
추가로
- memory에서 free 항목은 해당 OS의 실제 남은 메모리를 의미한다.
- system 항목은 시스템 콜 및 인터럽트에 관련된 정보를 보여준다.
- cpu 항목은 CPU 사용률을 나타낸다.
Load Average가 시스템에 끼치는 영향
같은 수치의 Load Average라고 해도 그 원인에 따라 영향이 다를 수 있다.
간단한 테스트
nginx와 java를 통해서 간단한 GET 요청 처리 세팅을 한다.
그리고 각각 CPU 기반의 부하와 I/O 기반의 부하를 일으키도록 한다.
테스트 결과, CPU 기반의 부하는 응답 속도가 9~10초, I/O 기반의 부하는 응답 속도가 8초 초반대가 나왔다.
*top 명령을 통해 nginx, java, 스크립트 파일 각각이 얼마만큼의 CPU를 사용하고 있는지 확인이 가능하다.
이처럼 프로세스가 어떤 시스템 자원을 많이 쓰느냐에 따라서 부하가 시스템에 미치는 영향이 다르다.
정리
- Load Average는 실행 중 혹은 실행 대기 중이거나 I/O 작업 등을 위해 대기 큐에 있는 프로세스들의 수를 기반으로 만들어진 값이다.
- Load Average 자체의 절대적인 높음과 낮음은 없으며 현재 시스템에 장착되어 있는 CPU 코어를 기반으로 한 상대적인 값으로 해석해야 한다.
- 커널에도 버그가 있으며 Load Average 값을 절대적으로 신뢰해서는 안된다.
- vmstat 툴 역시 시스템의 부하를 측정하는 데 사용될 수 있으며 r과 b를 눈여겨볼 필요가 있다.
- /proc/sched_debuf는 vmstat 툴을 통해 확인할 수 있는 것보다 더 자세한 정보들을 제공해주며 특히 nr_running과 runnable tasks 항목에서는 각 CPU에 할당된 프로세스 수와 프로세스의 PID 등의 정보를 확인할 수 있다.
<참고>
DevOps와 SE를 위한 리눅스 커널 이야기
uptime: https://access.redhat.com/ko/articles/3118571
vmstat: https://waspro.tistory.com/155
'Study > Linux' 카테고리의 다른 글
| [Linux]swap (0) | 2024.04.14 |
|---|---|
| [Linux]free 명령과 메모리 (0) | 2024.04.10 |
| [Linux]top을 통해 살펴보는 프로세스 정보들 (0) | 2024.04.06 |
| [Linux]시스템 구성 정보 확인 (1) | 2024.04.03 |
| [Linux]gcc 컴파일 (0) | 2020.12.16 |