k-최근접 이웃 알고리즘
분류와 회귀에 사용
- 분류: 출력은 소속된 항목, 객체는 k개의 최근접 이웃 사이에서 가장 공통적인 항목에 할당되는 객체로 과반수 의결에 의해 분류
- 회귀: 출력은 객체의 특성 값, k개의 최근접 이웃이 가진 값의 평균
k=3 일 때는 해당 데이터가 Class B인 보라색으로 분류됨
k=6 일 때는 해당 데이터가 Class A인 노란색으로 분류됨
즉, KNN은 k를 어떻게 정하냐에 따라 결과값이 바뀔 수 있음
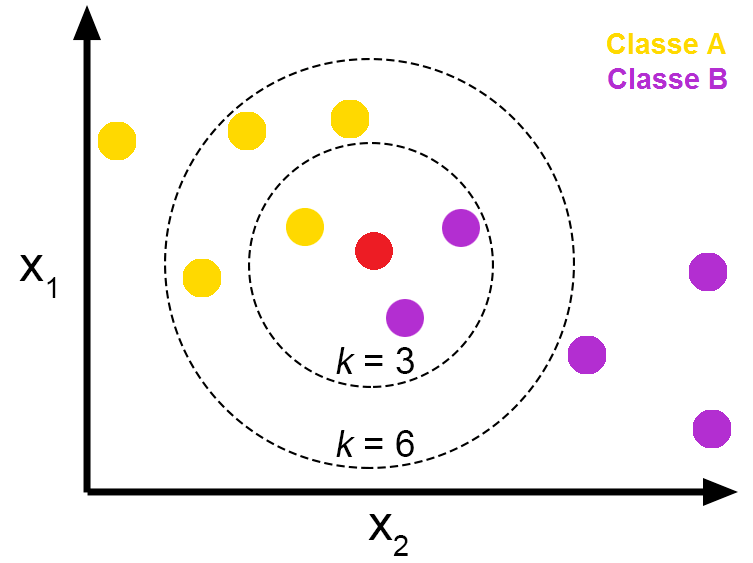
k가 너무 작아도 안되고, 너무 커도 안됨
k의 dafault 값은 5이며, 일반적으로 홀수를 사용함
더 가까운 이웃일수록 더 먼 이웃보다 평균에 더 많이 기여하도록 이웃의 기여에 가중치를 주는 것이 유용
단순하기 때문에 다른 알고리즘에 비해 구현이 쉬움
훈련이 따로 필요하지 않음
사전 모델링이 필요하지 않음
그렇기 때문에 훈련 단계가 매우 빠르게 수행됨
그러나 데이터의 지역 구조에 민감한 것이 단점
생각해 봐야할 문제들
1. 정규화
모든 특성들을 모두 고르게 반영하기 위해 사용
가장 대표적인 2가지 방법
- 최소값을 0, 최대값을 1로 고정한 뒤 모든 값들을 0과 1사이 값으로 변환하는 방법
- 평균과 표준편차를 활용해서 평균으로부터 얼마나 떨어져 있는지 z-점수로 변환하는 방법
2. k 개수
앞서 언급했듯이 k를 몇으로 정할지도 중요함
모든 값을 실제로 테스트하면서 분류 정확도(Accuracy)를 계산하는 과정에서 알 수 있음
k가 너무 작으면 Overfitting(과적합) 발생
k가 너무 크면 Underfitting(과소적합) 발생

실습
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
iris = load_iris(as_frame = True)
df = iris.frame
df.head()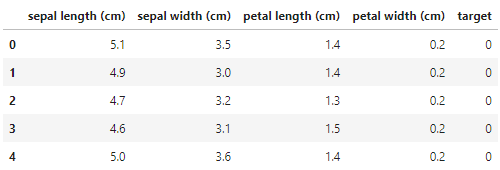
def setcolor(s):
color = []
colors = ['b', 'g', 'r']
for i in s.values:
color.append(colors[i])
return color
plt.figure(figsize=(5,5))
plt.scatter(x=df['petal length (cm)'],
y=df['petal width (cm)'],
color = setcolor(df['target']))
plt.xlim(df['petal length (cm)'].min()-0.1, df['petal length (cm)'].max()+0.1)
plt.ylim(df['petal width (cm)'].min()-0.1, df['petal width (cm)'].max()+0.1)
plt.show()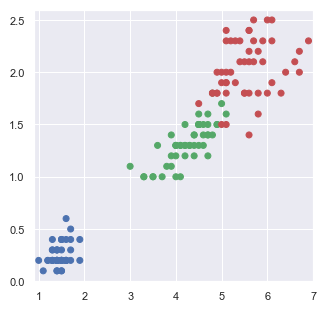
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = df.iloc[:, :4]
scaler.fit(data)
s = scaler.transform(data)
sdf = pd.DataFrame(s, columns=df.columns[:-1])
sdf['target'] = df.target
sdf.head()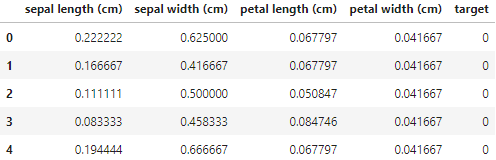
plt.figure(figsize=(5,5))
plt.scatter(x=sdf['petal length (cm)'],
y=sdf['petal width (cm)'],
color = setcolor(sdf['target']))
plt.axis([-0.1, 1.1, -0.1, 1.1])
plt.show()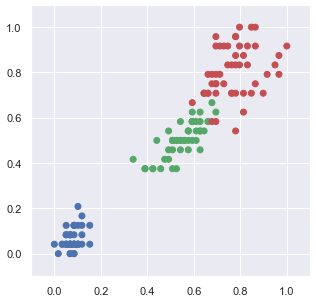
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
X_train, X_test, y_train, y_test = train_test_split(sdf.iloc[:, :-1], sdf['target'], test_size=0.33)
from sklearn.neighbors import KNeighborsClassifier
#k=5
model = KNeighborsClassifier(n_neighbors=5, weights='distance')
model.fit(X_train, y_train)
def dispConfusionMatrix(y_true, y_pred):
sns.heatmap(confusion_matrix(y_true, y_pred), annot=True )
plt.xlabel('Predicted')
plt.ylabel('Ground truth')
plt.show()
dispConfusionMatrix(y_test, pred)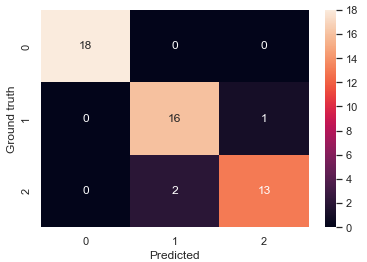
edf = df.iloc[(y_test[y_test != pred]).index, :]
#데이터 & 예측결과 표시하기
plt.figure(figsize=(5,5))
plt.scatter(x=df['petal length (cm)'],
y=df['petal width (cm)'],
color = setcolor(sdf['target']),
alpha = 1) #불투명
plt.scatter(x=edf['petal length (cm)'],
y=edf['petal width (cm)'],
color = 'k',
alpha = 0.4)
plt.show()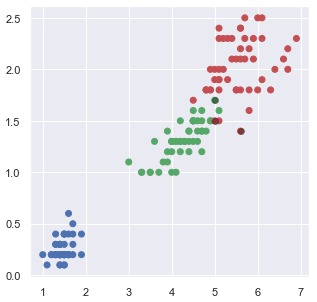
아래의 링크들에도 실습 코드들이 있으니 참고!
출처
https://hleecaster.com/ml-knn-concept/
https://hleecaster.com/ml-knn-regression-example/
https://hleecaster.com/ml-knn-classifier-example/
'Study > AI' 카테고리의 다른 글
| [AI][ML]나이브 베이즈(Naive Bayes) (0) | 2022.08.10 |
|---|---|
| [AI][ML]SVM(Support Vector Machine) (0) | 2022.08.10 |
| [AI][ML]Logistic Regression(로지스틱 회귀) (0) | 2022.07.31 |
| [AI][ML]회귀(Regression) (0) | 2022.07.29 |
| [AI][ML]상관계수 (0) | 2022.07.20 |