스케일링
모든 특성의 범위(또는 분포)를 같게 만들어주기 위함
특성별로 데이터의 스케일이 다르다면, 머신러닝이 잘 동작하지 않을 수 있다.
데이터가 가진 크기와 편차가 다르기 때문에 한 피처의 특징을 너무 많이 반영하거나 패턴을 찾아내는데 문제가 발생하기 때문이다.
표준화(Standardization)
표준정규분포의 속성을 갖도록 피처가 재조정되는 것
0 주위에 표준편차 1의 값으로 배치되도록 피처를 표준화하는 것은 다른 단위를 가진 측정값을 비교할 때 중요할 뿐만 아니라 많은 기계 학습 알고리즘의 일반적인 요구 사항
정규화(Normalization)
데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것
기계학습에서 모든 데이터셋이 정규화 될 필요는 없고, 피처의 범위가 다른 경우에만 필요
통상적으로는 표준화를 통해 이상치를 제거하고, 그 다음 정규화 해 상대적 크기에 대한 영향력을 줄인 다음 분석을 시작한다
scikit-learn의 scaler
fit과 transform 메서드
fit 메서드는 훈련 데이터만 적용해, 훈련 데이터의 분포를 먼저 학습하고,
transform 메서드를 훈련 데이터와 테스트 데이터에 적용해 스케일을 조정
따라서, 훈련 데이터에는 fit_transform() 메서드를 적용하고, 테스트 데이터에는 transform() 메서드를 적용
fit()은 데이터를 학습시키는 메서드, transform은 실제로 학습시킨 것을 적용하는 메서드
fit_transform()은 fit() 과 transform() 함께 수행하는 메소드
테스트 데이터에 fit_transform()을 적용해서는 안됨
이를 수행하면 scaler 객체가 기존에 학습 데이터에 fit 했던 기준을 모두 무시하고 다시 테스트 데이터를 기반으로 기준을 적용하기 때문이다.
이러한 번거로움을 피하기 위해 학습과 테스트 데이터로 나누기 전에 먼저 Scaling등의 데이터 전처리를 해주는 것이 좋음
StandardScaler()
평균을 제거하고 단위 분산에 맞게 조정하여 기능을 표준화한다.
모든 피처의 평균을 0, 분산을 1로 스케일링
→ 기존 변수의 범위를 정규분포로 변환하는 것
데이터의 최소 최대를 모를 때 사용
이상치가 있다면 평균과 표준편차에 영향을 미치기 때문에 데이터의 확산이 달라지게 됨
→ 이상치가 많다면 사용하지 않는 것이 좋음
회귀보다 분류에 유용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(data1)
s_data = scaler.transform(data1)
RobustScaler()
이상치에 대해 강력한 통계를 사용하여 기능을 확장
모든 피처가 같은 크기를 갖는다는 점이 standard와 유사
그러나 평균과 분산이 아닌 중위수(median)과 IQR(사분위수)를 사용함
- 중간 값은 정렬 시 중간에 있는 값, 사분위값은 1/4, 3/4에 위치한 값을 의미
이상치 영향을 최소화할 수 있음
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaler.fit(data1)
r_data = scaler.transform(data1)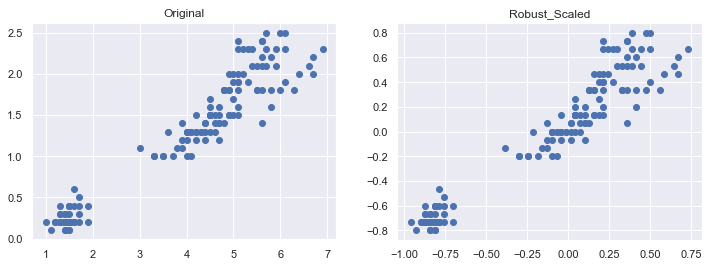
MinMaxScaler()
Min-Max Normalization이라고도 불림
각 기능을 지정된 범위로 확장하여 기능을 변환
데이터의 값들을 0~1 사이의 값으로 변환
각 변수가 정규분포가 아니거나 표준 편차가 작을 때 효과적
그러나 StandardScaler와 같이 이상치 존재에 민감
분류보다 회귀에 유용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data1)
m_data = scaler.transform(data1)
MaxAbsScaler()
최대 절대값으로 각 기능의 크기를 조정
각 특성의 절대값이 0과 1사이가 되도록 스케일링
즉, 모든 값은 -1과 1 사이로 표현되며, 데이터가 양수일 경우 MinMaxScaler와 동일
이상치에 매우 민감함
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data1)
m_data = scaler.transform(data1)
Normalizer()
앞의 4가지 스케일러는 각 특성(열)의 통계치를 이용하여 진행
그러나 이는 각 샘플(행)마다 적용되는 방식
샘플을 개별적으로 단위 표준으로 정규화
한 행의 모든 특성들 사이의 유클리드 거리(L2 norm)가 1이 되도록 스케일링
각 변수의 값을 원점으로부터 1만큼 떨어져 있는 범위 내로 변환
→ 빠르게 학습할 수 있고 과대적합 확률을 낮출 수 있음
데이터 전처리의 상황에서 사용되는 것이 아니라 모델 내 학습 벡터에 적용
피처들이 다른 단위를 가지면 사용하지 않음
from sklearn.preprocessing import Normalizer
scaler = Normalizer()
scaler.fit(data1)
n_data = scaler.transform(data1)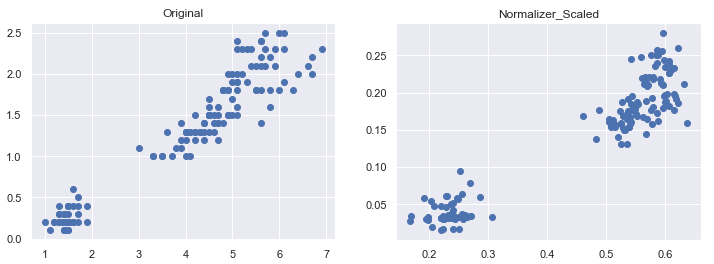
출처
'Study > AI' 카테고리의 다른 글
| [AI][ML]회귀(Regression) (0) | 2022.07.29 |
|---|---|
| [AI][ML]상관계수 (0) | 2022.07.20 |
| 로지스틱 회귀 (0) | 2022.06.04 |
| [AI]작업 흐름 (0) | 2021.02.09 |
| [AI][Deep learning]행렬의 내적(행렬 곱) (0) | 2021.02.06 |